Regressionsanalyse
Dette indlæg er skrevet til WebMatematik, hvor målgruppen er gymnasieelever. Indholdet bør være korrekt men ikke nødvendigvis med 100% fyldestgørende forklaringer.
Introduktion
Fra simpel lineær regressions analyse ved vi, hvordan man med mindste kvadraters metoden bestemmer den lineære funktion, som bedst passer til en række observationer i 2D planen.
Vi har altså her observationer $(y_i, x_i)$ for $i=1,\ldots,n$ og ønsker at bestemme konstanterne $a$ og $b$ på en sådan måde, at den lineære funktion \(y = a + b x\) ligger så tæt på alle observationer $(y_i, x_i)$ som muligt.
Verden er dog sjældent så simpelt indrettet, at man kan beskrive en afhængig variabel $y$ med kun en enkelt forklarende variabel $x$.
Multipel regression er en udvidelse af simpel regression, hvor vi i stedet for en enkelt forklarende variabel har to eller flere forklarende variable. Forklarende variable kaldes til tider også for kovarianter mens afhængige variable somme tider omtales som respons variable.
Model
Vi har $n$ observationer $y_i,x_{i1},x_{i2},\ldots,x_{ip}$ hvor $i=1,\ldots,n$ og ønsker at bestemme konstanter $b_0,b_1,b_2,\ldots,b_p$, så funktionen \(y = b_0 + b_1 x_1 + b_2 x_2 + \cdots b_p x_p\) ligger så tæt på alle punkterne $y_i,x_{i1},x_{i2},\ldots,x_{ip}$ som muligt. Konstanterne kaldes for regressionskoefficienterne.
Bemærk, at der nu er et dobbelt indeks på $x$’erne. Det er nødvendigt, da vi nu har $p$ forklarende variable istedet for blot en enkelt forklarende variabel. Så når vi skriver \(x_{ij}, \quad i=1,\ldots,n \quad \textrm{ og } \quad j=1,\ldots,p\) er der tale om den $j$’te forklarende variable for den $i$’te observation. Vi kan stille observationerne op i en tabel
| Observation | Afhængig variabel | Forklarende variable | |||
|---|---|---|---|---|---|
| $Y$ | $X_1$ | $X_2$ | $\cdots$ | $X_p$ | |
| 1 | $y_1$ | $x_{11}$ | $x_{12}$ | $\cdots$ | $x_{1p}$ |
| 2 | $y_2$ | $x_{21}$ | $x_{22}$ | $\cdots$ | $x_{2p}$ |
| 3 | $y_3$ | $x_{31}$ | $x_{32}$ | $\cdots$ | $x_{3p}$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ | $\vdots$ |
| n | $y_n$ | $x_{n1}$ | $x_{n2}$ | $\cdots$ | $x_{np}$ |
for på den måde at vise, at vi har $p$ forklarende variable og $n$ observationer. Regressionskoefficienter bliver normal fundet (estimeret) ved brug af mindste kvadrater metoden, dvs man vælger $b_0, b_1, \ldots , b_p$ således at udtrykket \(\label{eq:sse} SSE =\sum^n_{i=1} {\big(y_i - b_0 - b_1 x_{i1} - b_2 x_{i2} - \cdots - b_p x_{ip} \big)}^2\) minimeres. SSE er engelsk for Sum of Squares Errors. Dette er samme fremgangsmetode som kendes fra simpel lineær regression. $b_0$ kaldes for skæringen og de øvrige $b$’er kaldes hældninger.
Formlen for koefficienterne $b_0,b_1,b_2,\ldots,b_p$ er noget mere kompliceret i det generelle tilfælde, så den springer vi over her. Men nedenfor gennengår vi et eksempel på, hvordan man kan bestemme koefficienter ved brug af Microsoft Excel.
Residualer
Når vi har bestemt regressionskoefficienterne $b_0,b_1,b_2,\ldots,b_p$ så kan vi udregnede de fittede værdier for observationerne $x_{i1},x_{i2},\ldots,x_{ip}$ hvor $i=1,\ldots,n$. For den $i$’te observation er den fittede værdi \(\widehat{y_i} = b_0 + b_1 x_{i1} + b_2 x_{i2} + \cdots b_p x_{ip}\) og vi definerer residualer som værende forskellen $e_i$ mellem observationen $y_i$ og den fittede værdi $\widehat{y_i}$ \(e_i = y_i - \widehat{y_i}\) Bemærk at ligning [eq:sse] også kan skrives \(SSE =\sum^n_{i=1} {\big(y_i - b_0 - b_1 x_{i1} - b_2 x_{i2} - \cdots - b_p x_{ip} \big)}^2 = \sum^n_{i=1} {\big(y_i - \widehat{y_i} \big)}^2 = \sum^n_{i=1} {e_i}^2\) så når vi finder minimum for $SSE$, så minimerer vi residualerne eller med andre ord - forskellen mellem de observerede og fittede værdier.
Visualisering af løsningen
I tilfældet med simpel regression bestemmer vi en ret linie som passer bedst til observationerne. Det er umuligt at visualisere multipel regression i det generelle tilfælde. For det særlige tilfælde, hvor vi har to forklarende variable $x_1$ og $x_2$ og dermed modellen \(y = b_0 + b_1 x_1 + b_2 x_2\) så kan vi stadig visualisere løsningen. Vi kan tænke på observationerne $(x_{i1}, x_{i2}, y_i), i=1,\ldots,n$ som punkter i rummet, dvs i 3D koordinatsystemet med akser $X_1, X_2$ og $Y$.
Løsningen er nu ikke længere en ret linie, men derimod den plan som ligger tættest på alle punkterne. På figuren kan vi også se residualerne de er plottet som linier mellem observationerne og planen. Nogle observationer ligger over planen og er markeret med en grøn linie, mens andre observartioner ligger under planen og er markeret med en rød linie. Det kan være svært ud fra en enkel vinkel at forestille sig, hvordan løsningen ud. Prøv at se på følgende optagelse, hvor vi kan se planen fra en række forskellige vinkler.
Eksempel
Lad os se på et (simplificeret) eksempel på multipel regressionsanalyse. Eksemplet er hentet fra opgaven “Prisdannelse på ejerlejligheder i København” af Vibeke Stål og Anne Melvej Stennevad. Forfatterne undersøger, om der er en lineær sammenhæng mellem prisen på ejerlejligheder i København og en række faktorer såsom fx rente og byggeomkostninger. \(\label{eq:model} \textrm{prisindeks} = b_0 + b_1 * \textrm{byggeomkostninger} + b_2 * \textrm{rente}\) Hvordan bestemmer man regressionskoefficienterne $b_0, b_1$ og $b_2$, hvis vi har observationer som vist her i Excel
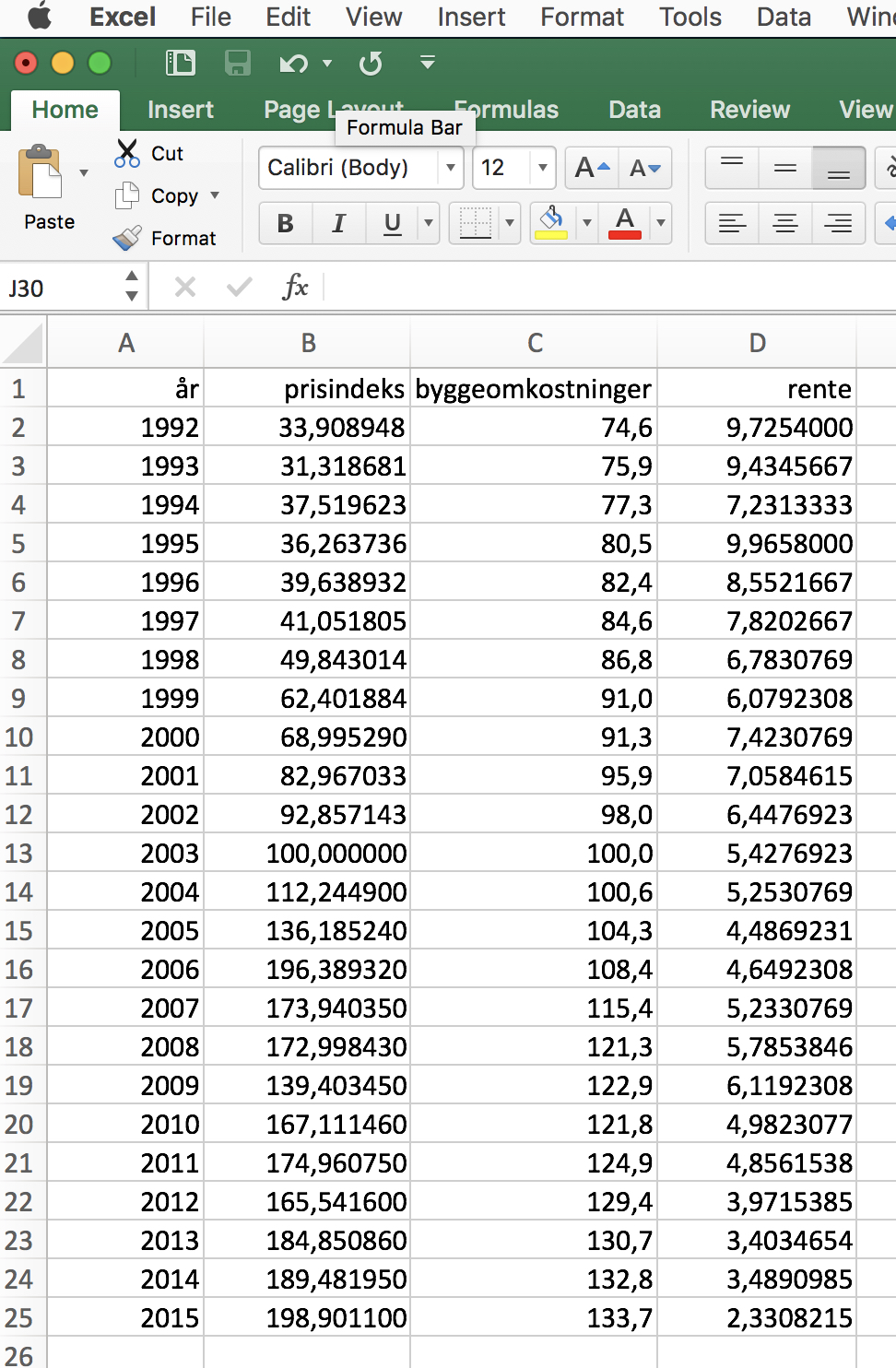
Hvis du selv ønsker at arbejde med dette datasæt, så kan det downloades via dette link.
I menuen under “Tools” finder man “Data Analysis”. Hvis Data Analysis ikke er en del af menuen, så er her en vejledning til hvordan man får den installeret i Excel.
og dernæst fås en oversigt over de forskellige analyseværktøjer. Vælg “Regression”
Så dukker denne regression menu op
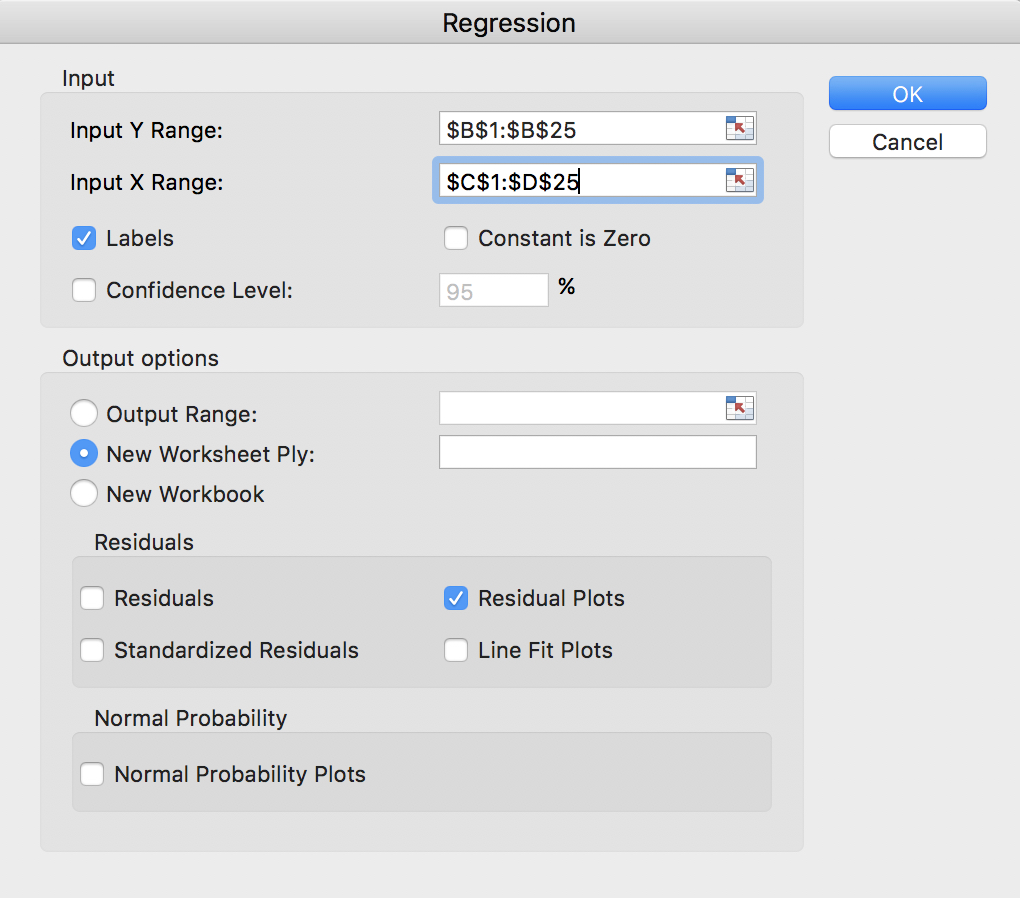
Her har vi som “Input Y Range” valgt kolonnen med prisindeks (inkl. overskriften). Dette er vores afhængige variable. Dernæst har vi som “Input X Range” valgt kolonnerne med data for byggeomkostninger og renter (igen inkl. overskrift). Ved at sætte kryds i “Labels” checkboksen fortæller vi Excel, at vores valg af inputdata indeholder overskrifter. Det gør det nemmere at læse resultaterne. Som det sidste vælger vi også “Residual Plots”.
Som udgangspunkt bliver alle resultater placeret i en nyt Excel sheet. Så er det lettere at slette dette sheet og begynde forfra, hvis man får behov for det.
Der er en masse output fra beregningen, men i første omgang fokuseres vi på regressionskoefficienterne

Indsætter vi de fundne koefficienter i model [eq:model] får vi regressionsligningen \(\textrm{prisindeks} = -90,95 + 2,35 * \textrm{byggeomkostninger} - 6,67 * \textrm{rente}\)
Efter at have bestemt selve modellen kigger vi på tallene under overskriften “Regression Statistics”:
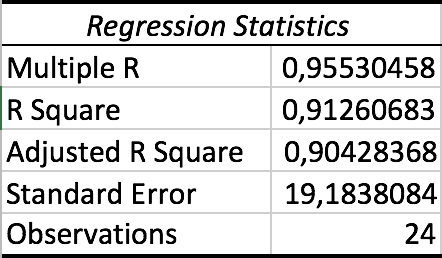
Her sætter vi fokus på Multiple R og R Square. På dansk kaldes disse to værdier for korrelations- og determinationskoefficienten.
Korrelationskoefficienten
Det er med Excel altid muligt at bestemme regressionskoefficienterne $b_0,b_1,b_2,\ldots,b_p$, så spørgsmålet er mere, om det giver mening at forsøge at modellere en lineær sammenhæng mellem en afhængig variable og en eller flere forklarende variable. Det kan korrelationskoefficienten hjælpe os med at afklare. I Excel betegnes korrelationskoefficienten med “Multiple R”. Men typisk bruger man blot betegnelsen R for korrelationskoefficienten.
Fortolkning af korrelationskoefficienten
Korrelation mellem to variable betyder, at hvis den ene variables ændre sig, så giver det en forudsigelig ændring i den anden variabel. Korrelationskoefficienten ligger altid mellem 0 og 1. Hvis den er 1, er der en deterministisk korrelation mellem variablene, dvs en ændring i den ene variabel vil helt sikkert medføre en ændring i den anden variable. Hvis værdien derimod er 0, så er der absolut ingen lineær sammenhæng mellem de to variable. Skematisk ser det ud som i tabel [tabel:correlation].
| Fortolkning | |
|---|---|
| 1,0 | Perfekt lineær sammenhæng |
| 0,0 | Absolut ingen lineær sammenhæng |
| 0,9 | Stærk lineær sammenhæng |
| 0,5 | Moderat lineær sammenhæng |
| 0,2 | Svag lineær sammenhæng |
Bemærk at en høj grad af korrelation på ingen måder kan bruges til at postulere en årsagssammenhæng (kausalitet) mellem variable. Se afsnittet TODO for mere information.
Hvis multipel lineær regression skal give mening, så skal der være en lineær sammenhæng mellem den afhængige variable og de forklarende variable. Hvis vi kigger på eksemplet fra tidligere, jvf tabel [tabel:resultat], så ser vi, at der her er en korrelationskoefficient på ca. 0,9553 og at der dermed i dette tilfælde er en korrelation mellem variable pris, byggeomkostninger og rente.
Formel for korrelationskoefficienten for to uafhængige variable
Den generelle formel for korrelationskoefficienten er kompliceret og involveret matrix beregninger. I tilfældet hvor vi kun har to uafhængige variable er det lidt nemmere at skrive formlen ned. \(\label{eq:correlation} R = \frac{\sqrt{r^2_{yx_1} + r^2_{yx_2} - 2r_{yx_1} r_{yx_2} r_{x_1x_2}}} {\sqrt{1 - r^2_{x_1x_2}}}\) hvor fx \(r_{yx_1} = \frac{\sum{(y - \bar{y})(x_1 - \bar{x_1})}}{(n-1)s_{yx_1}}\) og \(\bar{y} = \frac{y_{i}}{n}, \quad \bar{x_1} = \frac{x_{1i}}{n}, \quad s_{y} = \sqrt{\frac{\sum{(y_{i} - \bar{y})^2}}{n-1}}, \quad s_{x_1} = \sqrt{\frac{\sum{(x_{1i} - \bar{x_1})^2}}{n-1}}\) Størrelsen $r_{yx_1}$ er dybest set korrelationskoefficienten mellem variablene $y$ og $x_1$. Når formlen [eq:correlation] er mere kompleks skyldes det, at vi også er nød til at betragte korrelationen mellem $y$ og $x_2$ og mellem $x_1$ og $x_2$.
Pointen med at opskrive formlen er ikke, at du skal kunne regne korrelationskoefficienten i hånden. Pointen er derimod at kunne sammenligne med simpel regressionsanalyse. Hvis vi nu kun har en enkelt forklarende variable $x_1$ og $x_2=0$, så forsvinder de fleste led i formlen [tabel:correlation]. Tilbage bliver kun de led, hvor $x_2$ ikke indgår, dvs \(R = \frac{\sqrt{r^2_{yx_1}}}{\sqrt{1}} = r_{yx_1}\) hvilket præcis er korrelationskoefficienten for simpel lineær regression mellem den afhængige variabel $y$ og den forklarende variabel $x_1$.
Determinationskoefficienten
I Excel hedder determinationskoefficienten “R Square”, hvilket giver god mening, da formlen for determinationskoefficienten er kvadratet på korrelationskoefficienten, dvs \(\mathrm{determinationskoefficienten} = R^2\) Man hører jænvligt alternative betegnelser for determinationskoefficienten som fx forklaringsgraden eller tilpasningsgraden.
Alternativ formel
Der findes en alternativ formel for $R^2$ - som naturligvis giver samme værdi. Det er lettest at beregne determinationskoefficienten som kvadratet på korrelationskoefficienten men den alternative formel gør det nemmere at fortolke determinationskoefficienten.
Vi har tidligere set, at SSE er forskellen mellem de fittede og observerede værdier. På samme måde kan man definere SSR som værende forskellen på de fittede værdier og gennemsnittet af observationerne, dvs \(\textrm{SSR} = \sum_{i=1}^{n} \Big( \widehat{y_i} - \bar{y} \Big)\) Definitionen på den totale “Sum of Squares” er \(\textrm{SST} = \textrm{SSR} + \textrm{SSE}\)
For observationerne $y_i$ definerer man den totale “sum of squares” som \(\textrm{SS}_T = \sum_{i=1}^{n} \Big( y_i - \bar{y} \Big )\) hvor $\bar{y}$ er gennemsnittet af $y_i$’erne. Tilsvarende defineres “sum of squares” for regressions. Den alternative formel for $R^2$ er \(R^2 = \frac{SSR}{SST}\)
Fortolkning af Determinationskoefficienten
Vi har altså ligningen \(\begin{aligned} \textrm{SST} &= \textrm{SSR} + \textrm{SSE} \\ \textrm{Totale variation} &= \textrm{Forklaret variation} \\ &+ \textrm{Uforklaret variation}\end{aligned}\)
så formlen for $R^2$ er forholdet mellem den forklarede og totale variation i modellen. Så jo tættere $R^2$ er på 1, desto mere variation er forklaret af modellen. Hvis $R^2$ kommer meget tæt på 1 eller ligefrem bliver 1, så er der dog grund til ekstra omtanke. Se mere i afsnit ..
Residual plot
Det sidste output fra Excel som vi kigger nærmere på er residual plots. Husk at vi i menu [figure:regressionMenu] sætte kryds ved “Residual Plots”. Dette giver os disse to residual plots
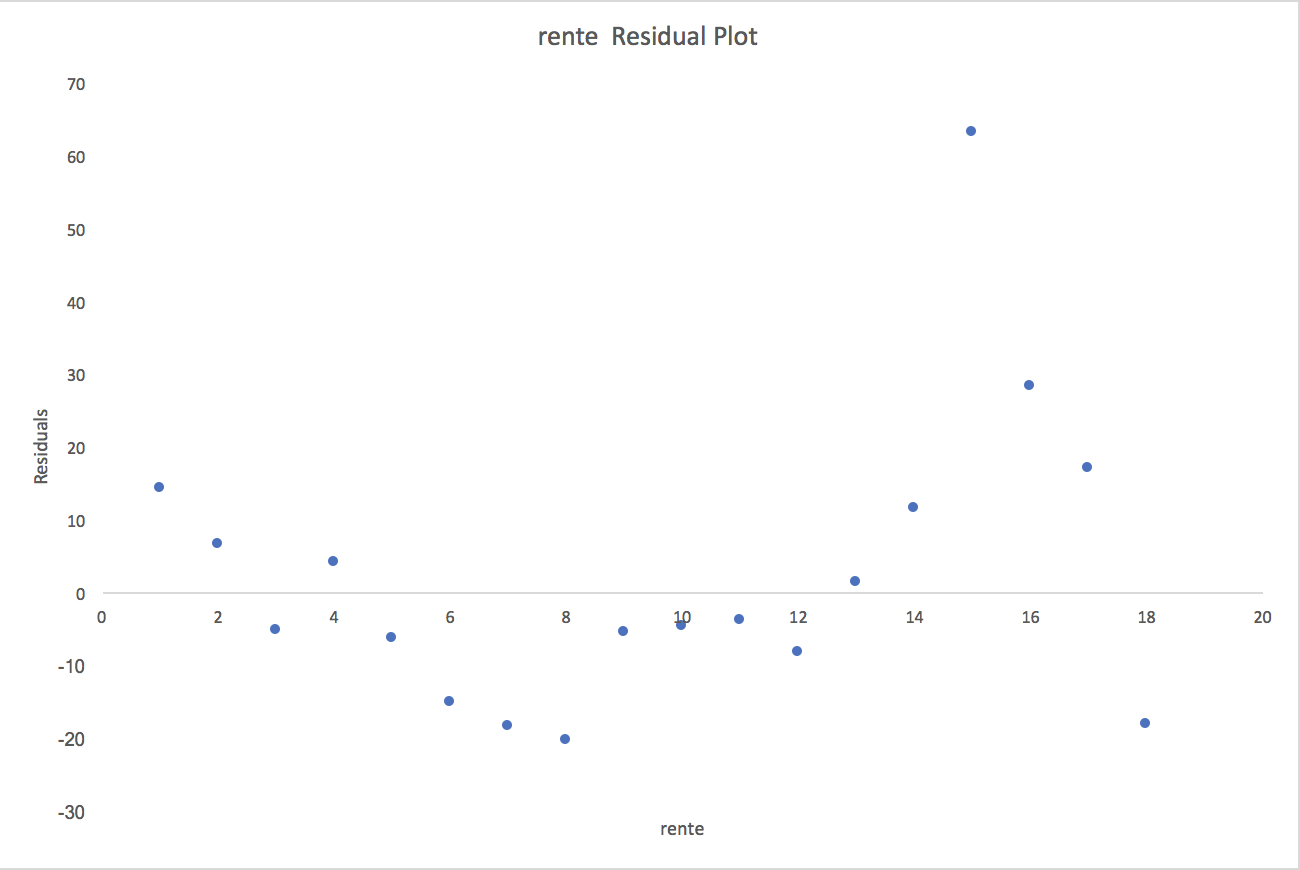
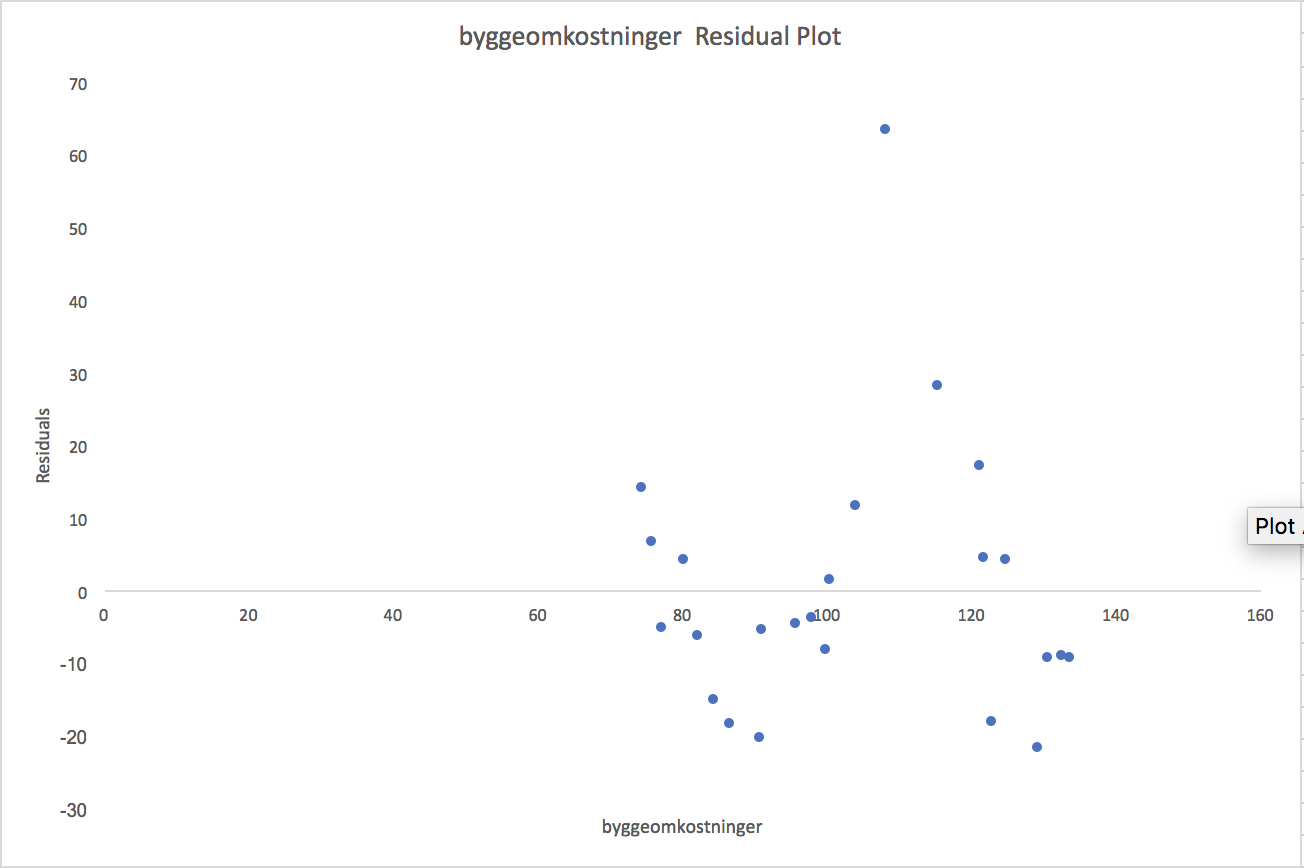
Husk at residualerne er forskellen mellem de fittede og observerede værdier. Hvis residual plottene virker helt tilfældige, så giver den mening at bruge en lineær model. Kan man derimod spotte en trend i residual plottet, som fx en ret linie eller et polynomium, så giver det ikke mening med en lineær model. Begge ovenstående plots virker tilfældige, så i vores eksempel giver det mening at bruge en lineær model.
Konfidensinterval for parametre
Vi har tidligere behandlet konfidensintervaller for middelværdier og sandsynslighedparameteren. Man kan også bestemme konfidensintervaller for regressionskoefficienterne. Faktisk er de en del af output, når man bruger Excel til regressionsanalyse. Kig igen på tabel [figure:regressionCoefficients] som indeholdt regressionskoefficienterne. Der er nogle kolonner med overskriften “Lower 95%” og “Upper 95%”. Tallene i disse kolonner er nedre og øvre grænse for et $100\% - 95\% = 5\%$ konfidensinterval omkring regressionskoefficienterne.
Det kan være lidt forvirrende, at kolonnerne “Lower 95%” og “Upper 95%” er gentaget to gange med samme værdier. Hvis du kigger på menuen i figur … kan du se, at man kan sætte kryds i “Confidence Level” og indtaste et konfidensniveau. Hvis man gør dette med fx 1% så får man kolonnerne v “Lower 95%” og “Upper 95%” samt “Lower 99%” og “Upper 99%”. Dvs som udgangspunkt får man altid 5% konfidensinterval med som resultat og derudover kan man få et ekstra interval efter eget valg.
Formel for konfidensinterval
Formel for $1 - \alpha$ konfidensintervallet for de enkelte regressionskoefficienter er \(b_i \pm t(v, 1 - \alpha / 2) \textrm{se}(b_i)\) Her er
-
$t$ t-test funktionen
-
$v$ er antallet af observationer minus antallet af regressionskoefficienter og
-
se$(b_i)$ er “standard error” for $b_i$
Størrelsen se$(b_i)$ er svær at regne ud i hånden og formlen involvere matrix beregninger. Men kig igen på tabel [figure:regressionCoefficients]. Faktisk er standard fejlen er del af output fra Excel. t-test funktionen er indbygget i Excel under navnet T.INV.2T.
Som eksempel kan vi regne et 90% konfidensinterval for $b_1$. Her er $v=24-3=21$, $\alpha=0,1$, se$(b_i) = 0,42$ og $b_1=2,35$, så konfidensintervallet bliver \(\begin{aligned} \Big[2,35 - \textrm{T.INV.2T(0,1;21)} * 0,42 ; 2,35 + \textrm{T.INV.2T(0,1;21)} * 0,42 \Big] &= \\ \Big[2,35 - 1,72 * 0,42 ; 2,35 + 1,72 * 0,42 \Big] &= \\ \Big[2,35 - 1,72 * 0,42 ; 2,35 + 1,72 * 0,42 \Big] &= \\ \Big[1,6276 ; 3,0724\Big]\end{aligned}\)
Avancerede emner
Disse emner falder udenfor pensum men for den nysgerrige er her en kort introduktion til emner, som er vigtige i forbindelse med regressionsanalyse.
Udforskende dataanalyse
Indenfor området data science arbejder man en del med udforskende dataanalyse. Dette indebærer, at man før man kaster sig hovedkuls ud i at vælge den ene eller anden model, så tager man sig tid til at undersøge data nærmere. Det giver fx ikke mening at bruge en lineær regressionsmodel, hvis man på en graf kan se, at der umuligt kan være en lineær sammenhæng mellem en afhængig variable og en forklarende variabel. Det er ikke helt nemt at afgøre om der kan være en lineær sammenhæng mellem en afhængig variable og flere forklarende variable. Så på nuværende tidspunkt er det bedste man kan gøre at undersøge om det er plausibelt at der er en lineær sammenhæng mellem ens afhængige varibel og de forklarende variable en for en.
Der findes et klassisk eksempel under navnet Anscombes kvartet, hvor statistikeren Francis Anscombe viser fire forskellige datasæt med næsten identiske deskriptive statistikker (som fx middelværdi og varians), men når man laver en graf for hver af datasættene, så for man meget forskellige grafer.
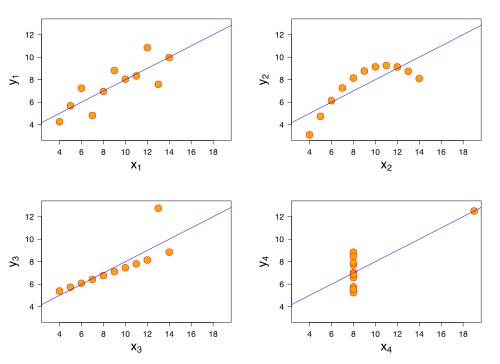
Grafen er fra “Anscombe’s quartet 3.svg. (2016, December 14). Wikimedia Commons, the free media repository”, hvor den original fil findes her.
{kind=link}
Model udvælgelse og multicollinearitet
Lad os sige, at vi har en model med en afhængig variabel og fire forklarende variable. \(y = b_0 + b_1 x_2 + b_2 x_2 + b_3 x_3 + b_4 x_4\) Hvordan kan vi være sikre på, at dette er den rigtige model. Måske skulle vi hellere udelade $x_2$ eller $x_3$ eller både $x_2$ og $x_3$. Sådanne spørgsmål forsøger man at besvare indenfor emnet model udvælgelse. Der findes en række statistiske tests som kan være med til at afgøre, om det er en god ide eller ej, at inkludere de enkelte variable.
Når man vælger de forklarende variable skal man også passe på med multicollinearitet. Dvs at ingen af de forklarende variable må kunne skrives som lineære funktioner af de øvrige forklarende variable. I eksempel med fire forklarende variable kan vi fx ikke have at \(x_2 = x_1 + x_4\)
Justeret $R^2$
I forlængelse af forrige afsnit om model udvælgelse er det værd at bemærke følgende. Hvis vi tilføjer flere forklarende variable til vores model, så vil det stort set næsten altid være sådan, at værdien af $R^2$ bliver større. Betyder det, at det altid er godt at tilføje flere forklarende variable til ens model? Hvis vi har $n$ observationer, så kan vi jo vælge en model med $n-1$ forklarende variable. Dette vil ofte give en værdi af $R^2$ meget tæt på 1. Så må det jo være en god model! Svaret er nej. Derfor bruger man ofte ikke determinationskoefficienten $R^2$ men en værdi som kaldes justeret $R^2$, når man skal se på om det giver mening at tilføje en ekstra variable til modellen.
Korrelation og kausalitet
Når vi arbejder med lineær regressionsanalyse leder vi efter korrelationer mellem den afhængige variable og en række forklarende variable. Det er meget vigtigt at have for øje, at en lineær sammenhæng mellem en række variable ikke er ensbetydende med en kausalitet eller årsagssammenhæng mellem de samme variable. På Videnskab.dk kan du finde en let tilgængelig artikel om korrelation og kausalitet og lære mere om forskellen samt hvad man skal passe på med.
Edit page on GitHub. Please help me to improve the blog by fixing mistakes on GitHub. This link will take you directly to this page in our GitHub repository.
There are more posts on the front page.

Content of this blog by Carsten Jørgensen is licensed under a Creative Commons Attribution 4.0 International License.