Arkitektur ideer til en skalerbar platform for struktureret logging
Jeg har for nylig kigget på en case omkring logning, hvor en applikation asynkront skulle logge til en fil. Logning er for de flestes vedkommende næppe et kerne forretningsområde, hvorfor standard løsninger vil være at foretrække. Man bør fokusere på det som for alvor giver værdi!
Tidligere i år var jeg til et arrangement i Copenhagen .NET User Group, hvor Thomas Ardal fortalte om Serilog og Elasticsearch.
Serilog er et .NET bibliotek til struktureret logning. Hvis man for alvor skal skabe værdi af informationer i logfiler, skal man have en struktureret tilgang til det at danne logs. Informationerne i logfilerne kan ikke bare være fritekst, men skal have et fast format og struktur. Serilog giver selv dette lille eksempel på deres website:
var position = new { Latitude = 25, Longitude = 134 };
var elapsedMs = 34;
log.Information("Processed {@Position} in {Elapsed:000} ms.",
position, elapsedMs);som resulterer i dette JSON format:
{"Position": {"Latitude": 25, "Longitude": 134}, "Elapsed": 34}Hvordan det præsenteres i en log afhænger af, hvor man sender data hen.
Formatet som gives til log.Information metoden kan ses som et simpelt DSL[1] udvidelse af .NET platformen streng formattering.
Hvilke krav skal man stille til en log platform? Der er sikkert mange, og flere end jeg lige nævner her. Men personligt ville jeg kigge efter muligheden for at
- finde standard løsninger
- have support for struktureret logging
- samle logs fra mange forskellige systemer og applikation
- kunne korrelerer logs fra forskellige kilder
- håndtere ustabilitet i netværket uden at miste information
- lave visualisering og/eller dashboards
- analyse af begivenheder i noget der er tæt på realtid
På internettet er der rigtig meget snak om ELK stakken som en standard løsning for en log platform. Hovedparten af førnævnte krav er understøttet af ELK, og dette skal ikke være en detaljeret gennemgang af denne stak, men her kommer en ultrakort introduktion.
Elasticsearch
Elasticsearch er en server platform bygget på Apache Lucene. Platformen tilbyder fuld-tekst søgninger og real-time analytics via et HTTP web interface. Data gemmes i et skemafrit JSON format. Jeg har tidligere skrevet et kort anmeldelse af bogen Elasticsearch - The Definitive Guide. Elasticsearch dækker krav 1, 4, og 7.
Logstash
Logstash er en dataflow engine som kan processere logfiler og event data fra et utal af systemer. Arkitekturen i Logstash er bygget over ‘pipes and filter’ mønsteret, se fx [2].
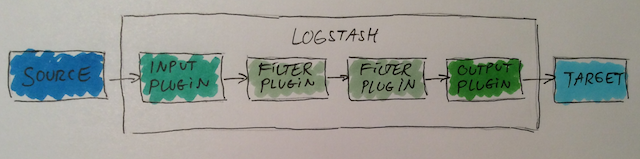
Plugins er hovedsageligt konfigurationsfiler som indlæses ved opstart af Logstash servicen. Logstash understøtter krav 1, 3, og 4.
Kibana
Kibana er en analyse og visualisering platform som kører i en webbrowser. Man kan i en vis forstand se Kibana som en ‘self-service’ platform, da det ikke kræver programmering at udvikle dashboards og visualiseringen. Dette foregår alt sammen via konfigurering i webbrowseren. Kibana understøtter krav 6 og 7.
Se fx denne artikel for et illustrativt lille eksempel på brugen af ELK stakken. ELK stakken er ikke .NET baseret, men den er supporteret på Windows.
Vi mangler at opfylde krav 2 og 5. Det er her, at Serilog 1 kommer ind i billedet med support for struktureret logning. Serilog kan faktisk sende data direkte til Elasticsearch, men vælger man den løsning mister den support som Logstash giver for en række andre datakilder, som ikke kan kommunikere direkte med Elasticsearch.
Hvorfor har vi egentligt det 5. krav? Tidligere i år deltog jeg i kurset Advanced Distributed Systems Design, hvor vi brugte det meste af en formiddag på at gennemgå de 8 fejlslutninger (fallacies) i distribuerede systemer. En af dem er
The network is reliable.
Hvis vi har et krav om at data ikke må gå tabt bliver vi nød til aktivt at understøtte det krav. Ellers vil vi før eller siden miste data pga ustabilitet i netværket.
Den udvidede dataflow for log informationer ender derfor med at være

Hvor vi udover ELK stakken og Serilog har tilføjet et message queue til persistering af logfiler.
Som message queue tænker jeg på at bruge RabbitMQ som dels har et input plugin til Logstash og RabbitMQ har fint support på .NET platformen. Her er en fin serie på 10 indlæg om brugen af RabbitMQ i C#. Derudover kan RabbitMQ sikre persistens af logbeskeder, og der er understøttelse for publish / subscribe, så man kan sende logs asynkront til RabbitMQ fra ens C# applikation.
Hvis man ikke har brug for at persistere logfiler ville jeg overveje Redis som et alternativ til RabbitMQ. Redis er in-memory, hvilket giver god performance. Hvis man ikke er bundet af Windows platformen kunne det også være interessant at kigge nærmere på Kafka. Logstash har input plugins til både Redis og Kafka.
Den overordnede arkitektur ender med at være som her

Den eneste komponent i løsningen som vi endnu ikke har talt om er ‘shipper’ 2. Et udtryk som man bruger hvis fx App 1 af en eller anden grund ikke kan kommunikere direkte med RabbitMQ, og derfor har brug for en alternativ måde at kommunikere med RabbitMQ på.
Det samlede dataflow minder på rigtig mange måder og Extract, Transform, Load (ETL) processen fra data warehouses.
Da så godt som alle elementer i arkitekturen er standard løsninger vil de formodentligt uden videre kunne indarbejde i et devops scenario med fx Puppet.
Referencer
[1] Martin Fowler. Domain-specific language. Addison-Wesley Professional, 2010.
[2] Gregor Hohpe og Bobby Woolf. Enterprise Integration Patterns. Designing, Building, and Deploying Messaging Solutions. Addison-Wesley Professional, 2004.
[3] Jay Krebs. I Heart Logs. Event Data, Stream Processing, and Data Integration. O’Reilly, 2015.
[4] Martin Kleppmann. Using logs to build a solid data infrastructure.
[5] Jay Krebs. The Log: What every software engineer should know about real-time data’s unifying abstraction.
Links
Load Balancing Logstash With AMQP
Using logstash, ElasticSearch and log4net for centralized logging in Windows
Dr. Strangelog (or: How I learned to stop worrying and Love the Logs)
ActiveMQ as a Message Broker for Logstash
Fodnoter
Edit page on GitHub. Please help me to improve the blog by fixing mistakes on GitHub. This link will take you directly to this page in our GitHub repository.
There are more posts on the front page.

Content of this blog by Carsten Jørgensen is licensed under a Creative Commons Attribution 4.0 International License.